比赛说明
The sinking of the Titanic is one of the most infamous shipwrecks in history.
On April 15, 1912, during her maiden voyage, the widely considered “unsinkable” RMS Titanic sank after colliding with an iceberg. Unfortunately, there weren’t enough lifeboats for everyone onboard, resulting in the death of 1502 out of 2224 passengers and crew.
While there was some element of luck involved in surviving, it seems some groups of people were more likely to survive than others.
In this challenge, we ask you to build a predictive model that answers the question: “what sorts of people were more likely to survive?” using passenger data (ie name, age, gender, socio-economic class, etc).
一、数据分析
数据的下载与观察
-
特征说明
| Varialbe | Definition | Key |
|---|---|---|
| survival | Survival | 0 = NO, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
特征详情
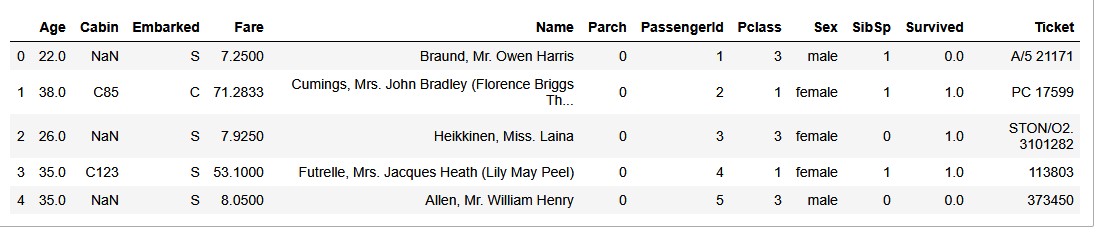
二、数据工程
特征处理
我们首先看看数据有没有缺失值:

发现’Age’、‘Cabin’、'Embarked’和’Fare’有缺失值:
- 'Embarked’用众数填充;
- 'Fare’和’Pclass’相关,所以用和缺失值相同的’Pclass’样本的’Fare’中位数填充;
- 'Cabin’缺失值,用是否有’Cabin’为依据来填充,'Cabin’不为空填1,为空填0;
- 'Age’我们用构建其他特征的方式来处理;
我们通过提取’name’中的称呼,构建了一个特征’Title’:

查看’Master’的’Age’,可以看出’Master’是小男孩,我们希望把小女孩也找出来:
|
|
最后,我们根据’Title’来的’Age’中位数来填充’Age’的缺失值:
|
|
现在我们完成了了对缺失值的处理。
构建新特征
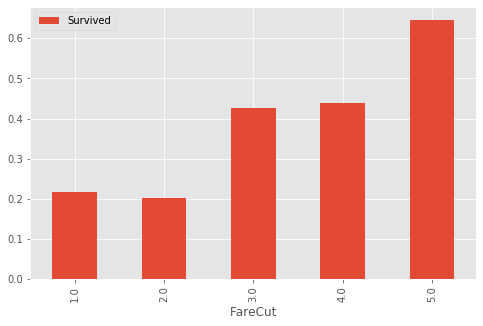
- 对’Fare’进行分箱,构建’FareCut’
- 对’Age’进行分箱,构建’AgeCut’
|
|
再将’Title’, 'Parch’和’Pclass’综合考虑,看看存活率。
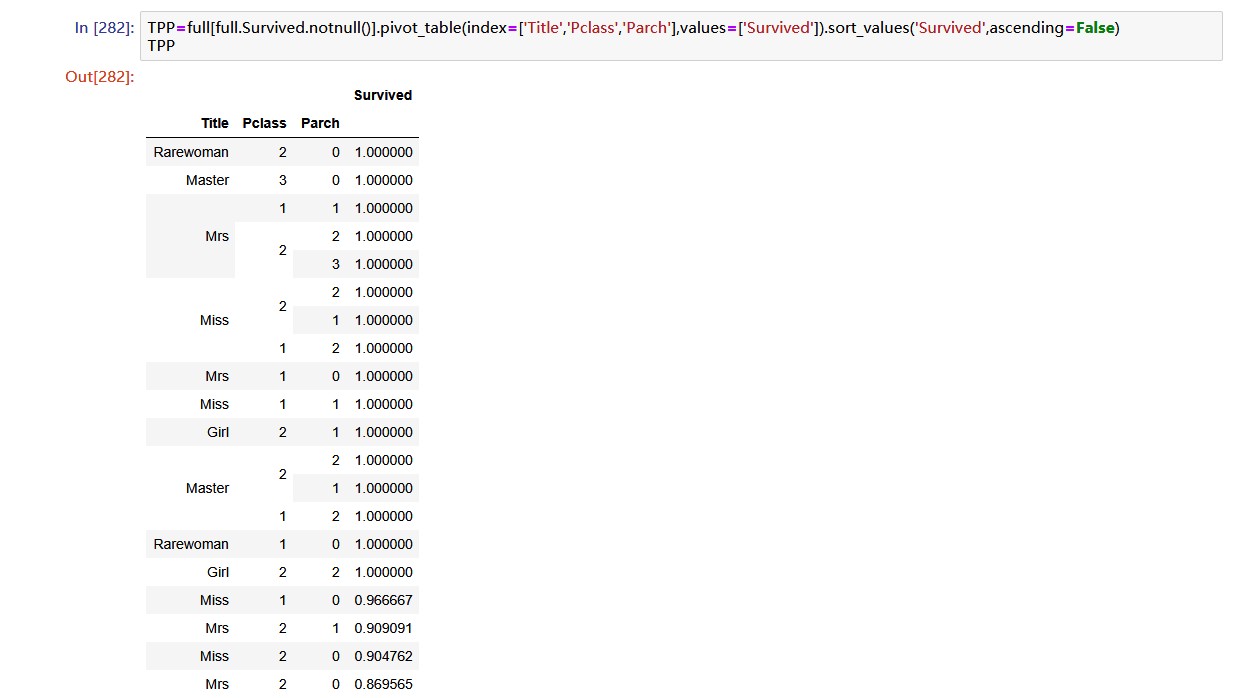
构建特征’TPP’:
|
|
三、建立模型
使用交叉验证法来训练模型,模型包括:
- KNN
- Logistic Regression
- Random Forest
- SVM
- Gradient Boosting Decision Tree
|
|
得出结果:
-
KNN:
- mean:0.81
- [0.82122905 0.77653631 0.80337079 0.80898876 0.83615819]
-
LR:
- mean:0.83
- [0.82681564 0.81564246 0.8258427 0.83146067 0.86440678]
-
RF:
- mean:0.81
- [0.82681564 0.77653631 0.84269663 0.76966292 0.83615819]
-
GBDT:
- mean:0.84
- [0.8547486 0.80446927 0.86516854 0.80337079 0.87570621]
-
SVM:
- mean:0.83
- [0.82681564 0.82681564 0.83146067 0.79775281 0.8700565]
可以看出, GBDT的表现最好。
我们在对分类错误的样本进行观察:
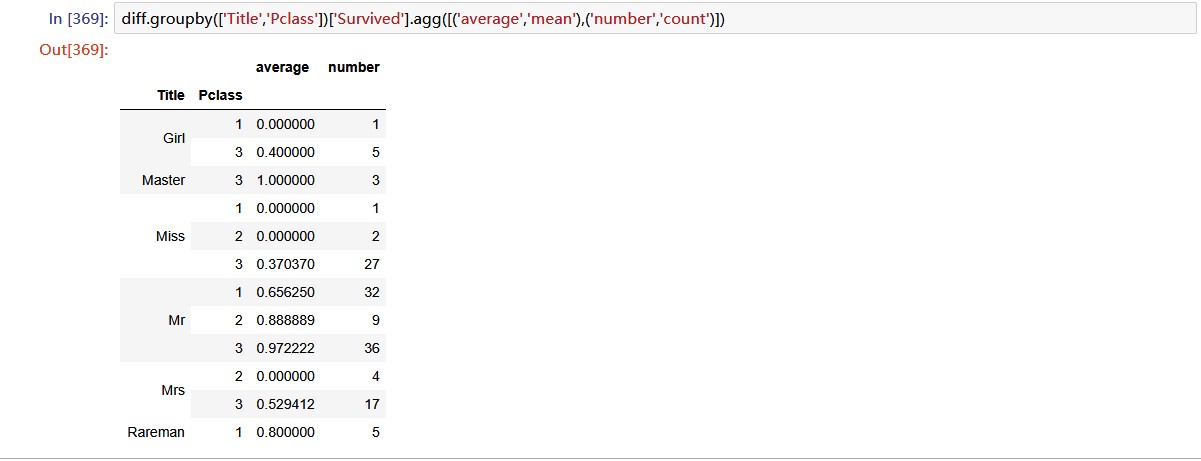
我们重点关注那些错误分类数目多的样本,就是:
- ‘Mr’,‘Pclass 1’,‘Parch 0’,‘SibSp 0\1’, 17+8
- ‘Mr’,‘Pclass 2\3’,‘Parch 0’,‘SibSp 0’, 32+7
- ‘Miss’,‘Pclass 3’,‘Parch 0’,‘SibSp 0’, 21
我们再构造一个特征’MPP’:
|
|
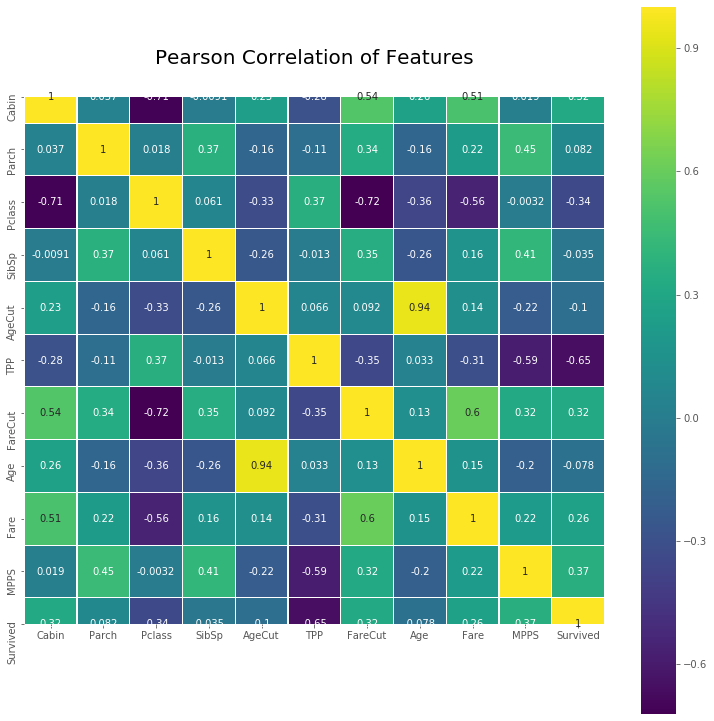
最后画一下相关系数热图:
四、模型优化
下面利用网格搜索来查找表现好的模型和模型参数:
|
|
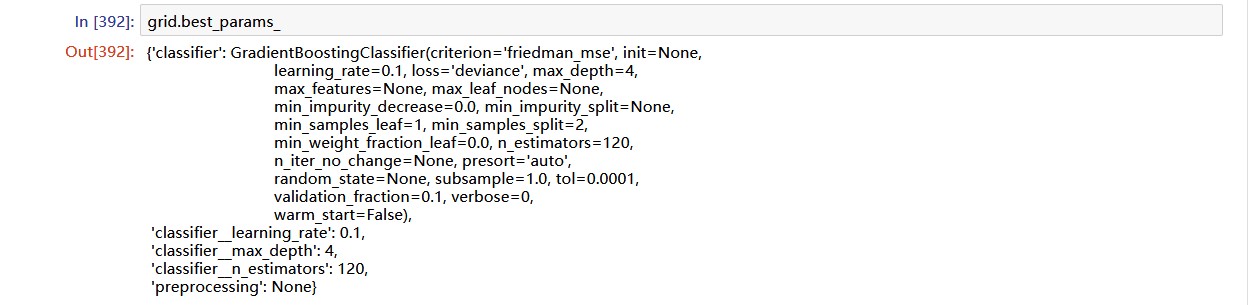
现在我们找到了表现最好的模型和对应参数,下面我们来对测试集进行预测:
|
|